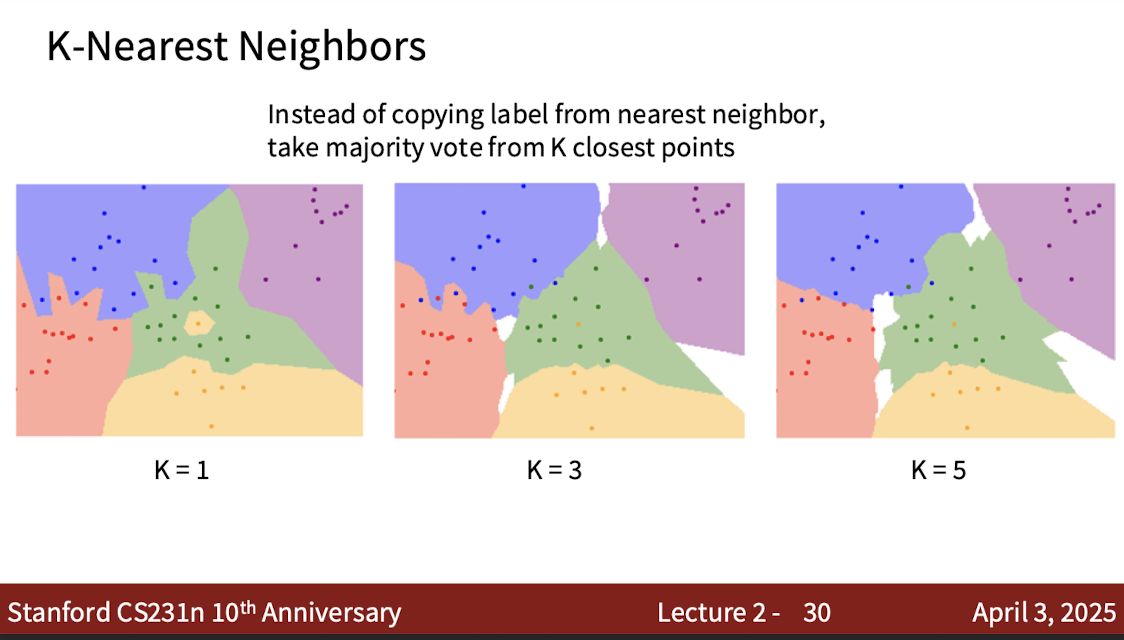
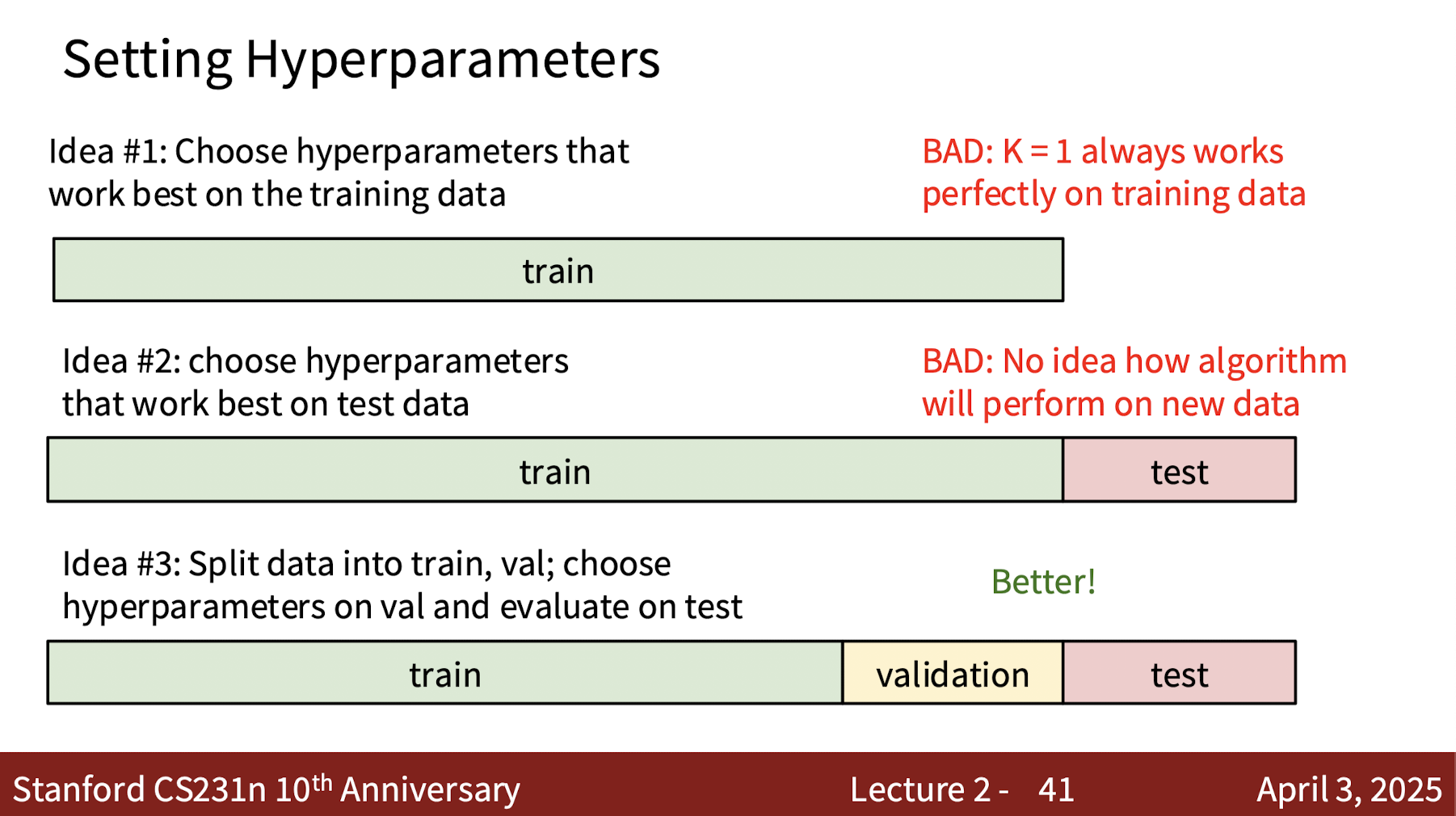
0. Recap



1. Neural Networks

우리가 알고 있는 linear classifier의 수식은 위와 같다.
이때 차원을 집중해서 보자. Input x의 차원이 D일때, Weight matrix의 차원은 CxD이다. 여기서 C는 Class라고 생각하면 된다.

이번에는 2 layer Neural Network를 보자.
수식이 위와 같을 때, 이번에도 차원을 살펴보면 H가 새로 정의된 것을 볼 수 있다.
H값을 통해 설계하는 hidden layer / nodes의 수가 정해진다.
그리고 또하나, max operation을 확인할 수 있는데, 이는 즉 W1, W2에 의한 linear operation 사이에 non-linearity가 추가된 것으로 볼 수 있다.

레이어를 더 쌓아서 더 정교하게 만들 수도 있다.

이러한 Neural Network를 학습시킨다는 것은, 학습 데이터에 해당하는 템플릿을 배우는 것이다.

다시 수식을 더 살펴보면, 여기서 max function은 activation function의 역할을 한다고 할 수 있다.
Activation function은 Neural Network에 있어서 매우 중요한 역할을 하는데, 만약 max function이 없다고 가정해보자.
그러면 이 수식은 그저 linear function과 같은 역할을 할 뿐이다.
Activation functions

다양한 activation 함수들이 있는데 우리가 본 함수는 ReLU 함수이다.
매우 유명하고 자주 사용되나, 단점은 음수에 대해서는 모두 출력이 0이 되므로 dead neuron을 만들 수 있다는 점이다.
이를 해결하기 위한 방법으로 Leaky ReLU, ELU, GeLU, SiLU 등이 제시되었다.
Sigmoid, tanh 또한 자주 사용되는 activation function이지만, 그래프를 보면 기울기가 나타나는 범위가 narrow하기 때문에, gradient vanishing 문제로 이어질 수 있다는 문제가 있다.
따라서 두 함수는 neural network 중간에는 잘 쓰이지 않고, 마지막에 output을 binarize 하는 목적으로 종종 쓰인다.

정리하자면 Neural Network의 구조는 위와 같다.
Activation function을 정의하면 hidden layer에서 그 값을 계산하고 output을 내보내는 형태이다.

20 Lines의 파이썬 코드로 작성한 2-layer Neural Network이다.

Hidden layer의 node 개수 변화에 따른 분류이다.
뉴런이 더 많을수록, 더 복잡한 함수 구현 및 분류가 가능해진다.

여기서 주의해야 할 점은 hidden layer의 수 또는 뉴런의 수(Neural Network의 크기)를 regularizer로 사용해선 안된다는 것이다.
즉 overfitting이 발생했다고 해서 네트워크의 크기를 조절하는 게 아니라, 우리가 이전에 배웠던 regularization loss의 λ에 해당하는 값을 조절하는 게 훨씬 효과적이다.
λ를 키울수록 regularization을 강화, 즉 W의 자유도를 더욱 규제하는 방향으로 더 generic boundary를 생성하는 것을 확인할 수 있다.

지금까지 내용을 정리하면,
1) 우리는 score function을 위와 같이 nonlinear하게 정의해 보았다.
2) 이렇게 나온 score 값을 Loss function에 넣어 Loss값을 구할 수 있다. (위에서는 hinge loss를 사용했지만 softmax 등 다양한 loss function 이 있음)
3) 추가적으로 Regularization을 정의해서 data loss와 더하면 최종 loss(Total loss) 값을 구할 수 있다.
최종 수식에서 $\frac{\partial L}{\partial W_1}, \frac{\partial L}{\partial W_2}$ 값을 계산할 수 있으면 W1, W2를 학습할 수 있다.

그 값은 backpropagation을 통해서 계산할 수 있다. 이 방법은 복잡한 neural network에서도 쉽게 적용될 수 있다는 점에서 매우 유용하다.
2. Backpropagation

간단한 예제를 활용한 backpropagation 문제이다.
$\frac{\partial f}{\partial x}$, $\frac{\partial f}{\partial y}$, $\frac{\partial f}{\partial z}$ 를 각각 computation graph를 통해 구한다.
이때 f와 y, f와 x는 바로 연결되어 있지 않으므로 chain rule을 적용하면 된다.

이때 backpropagation에서 하나의 노드를 통과할 때 chain rule이 어떻게 계산되는지 살펴보자.
- Local Gradient ($\frac{\partial z}{\partial x}$, $\frac{\partial z}{\partial y}$):
forward pass(순전파) 때 계산, 입력 변화에 대한 출력 변화율 - Upstream Gradient ($\frac{\partial L}{\partial z}$) :
출력값 z가 최종 손실 함수 L에 미친 영향 - Downstream Gradient ($\frac{\partial L}{\partial x}$, $\frac{\partial L}{\partial y}$) :
최종 Loss에 대해 입력값 x,y의 영향

또다른 예제를 보자. 복잡해보이지만 원리는 똑같다.
Computation graph에서 빨간 박스 안을 보자.
마찬가지로 Upstream gradient와 local gradient에 해당하는 값을 곱해주면 된다.

Addition의 경우도 각각 살펴보면 upstream gradient 값은 같고, local gradient의 경우 덧셈이므로 미분 결과 1을 곱해주면 된다.

주어진 수식을 하나하나 분해해서 computational graph를 만들었지만, 실제로 파란 박스에 해당하는 영역은 sigmoid function이다.
이걸 하나로 묶어서 gradient descent 를 계산해도 된다. Computational graph는 유일한 게 아니라 표현하는 방법이 다양하다.
참고적으로 슬라이드 하단에 sigmoid 함수를 미분한 결과이며, 이를 이용해 local gradient를 구할 수 있다.

지금까지 스칼라 값을 가지고 backpropagation 하는 법을 살펴보았다.
그렇다면 vector-valued function에 대해서는 어떻게 계산할 수 있을까?

그전에 참고적으로 보면 좋을 벡터 미분에 대한 내용이다.
$\frac{\partial y}{\partial x}$에서 x, y가 스칼라라고 하자. 계산 결과 또한 스칼라 형태이며, 의미적으로 보자면 x가 조금씩 변할 때 y값을 얼마나 변하느냐를 보고자 하는 것이다.
이번에는 x는 N의 길이를 가진 벡터, y는 스칼라이다. 미분 결과는 gradient 형태로 나오며, x의 각각의 요소가 변할 때 y 값이 얼마나 변하느냐를 의미한다.
마지막으로 x,y 둘 다 벡터라면 미분 결과는 NxM 행렬, Jacobian 형태로 나오며, x의 각각의 요소가 변할 때 y의 각각의 요소가 얼마나 변하느냐를 의미한다.

Input이 x,y 벡터이고 Output이 z 벡터일 때 backpropagation 과정을 보자.
이때 Loss 값은 여전히 scalar이다.
우선 Upstream gradient 에 해당하는 $\frac{\partial L}{\partial z}$는 Vector to Scalar에 해당하므로 gradient 결과값으로 나올 것이다.
Local gradient에 해당하는 $\frac{\partial z}{\partial x}$, $\frac{\partial z}{\partial y}$ 둘 다 Vector to Vector 이므로 Jacobian matrices 로 결과가 나오며, 그 크기는 input vector, output vector 사이즈에 따라 달라진다.
마지막으로 Downstream gradient의 경우, $\frac{\partial L}{\partial x}$, $\frac{\partial L}{\partial y}$ 는 둘 다 Vector to Scalar에 해당하므로 gradient 결과값으로 나오며, chain rule 적용이 필요하다.

위와 같은 예시를 보자. 이 슬라이드는 Forward pass 진행 과정이다.

해당 그래프에 대해 backpropagation을 진행하면 아래와 같이 나온다.
Local gradient를 계산하는 과정을 보면 각 요소가 서로 독립적으로 계산되므로 대각선 요소만 값을 가지는 대각 행렬 형태의 결과가 나온다는 것을 알 수 있다.

그러나 만약 입력 벡터의 차원이 4가 아니라 훨씬 큰 숫자였다면 야코비안 행렬의 크기가 매우 커져 메모리 문제가 발생할 것이다.
따라서 어차피 결과가 대각행렬이라는 점을 이용해 위 슬라이드의 수식처럼 입력 벡터 x의 부호에 따른 미분값을 구한 뒤, Upstream gradient와 곱셈만 해주면 똑같은 결과를 얻을 수 있다.

Input과 Output이 matrices (or tensor)인 경우에 대해서도 똑같이 backprop을 적용할 수 있다.

'AI > CS231N' 카테고리의 다른 글
| [CS231N] Lecture 3: Regularization and Optimization (0) | 2026.05.25 |
|---|---|
| [CS231N] Lecture 2: Image Classification with Linear Classifiers (0) | 2026.05.15 |
| [CS231N] Lecture 1: Deep Learning for Computer Vision (0) | 2026.05.11 |